影響個人醫療支出的因素:多元線性回歸分析與機器學習預測(R語言)
這是我碩一下修財管系開設「R : 程式、機率與統計」課程的期末報告,在R語言中對1338名美國國民資料建立多元回歸模型,並使用穩健標準誤解決異質變異數問題。實證結果中,抽菸者醫療支出比無抽菸者平均高出US$23,848。最後比較整體預測能力,其中XGboost(RMSE:4941)相較線性回歸(RMSE:6568)更精準,然而線性回歸預測某些樣本較佳,對此我們也提出解釋。
資料概述

資料來源為Kaggle上的個人醫療支出資料集,蒐集美國1338位國民橫斷面資料。特徵包含:年齡、性別、居住地區等基本資訊外,還有每個人的BMI與吸菸習慣。目標變數是每個人的醫療費用(由保險支出),是為連續變數。有了該資料集,我們就可以探討怎樣的人醫療支出會高。
單變量分析(Univariate Analysis)
由於性別、居住地區、吸菸習慣皆為類別變數,必須先對此變數one-hot encoing才能分析,否則會報錯。R code如下:
data$sex <- ifelse(data$sex=='male',1,0)
data$smoker <- ifelse(data$smoker=='yes',1,0)
data <- data %>%
mutate(southwest=ifelse(region=='southwest',1,0),
southeast=ifelse(region=='southeast',1,0),
northwest=ifelse(region=='northwest',1,0),
northeast=ifelse(region=='northeast',1,0))
data <- data %>% select(-region)
summary(data)
連續變數中,年齡(age)平均39歲,最小18歲,最大64歲。
BMI平均30,不過中位數也是30,這讓我有些驚訝,因為有一半以上的人都是肥胖(BMI30+)等級。我好奇查一下資料,發現美國CDC在2022年的資料顯示,美國肥胖率高達42%! 這實在非常驚人。
目標變數
「醫療支出(Charge)」的平均數為US$13,270,中位數$9,382。這個數字不誇張,美國醫療支出就是這麼貴,何況這可能是一個人目前為止累積的醫療費用(原始dataset並沒有說明是當期還是累積)。
另外平均數比中位數高,就代表該資料幾乎都集中在左邊,並且有稀疏的極大值,呈現一個右尾分布,如下圖。
hist_plot <- ggplot(data, aes(x = charges)) +
geom_histogram(fill = "#036564", color = "#033649", binwidth = diff(range(data$charges))/30) +
labs(title = "Distribution of charges", x = "x", y = "Pr(x)") +
theme_minimal()
print(hist_plot)
我想看看是否醫療支出也呈現80/20法則? 也就是說少數的人支出了大部分的醫療費用? 結果是前20%支出佔了51.68%的總醫療費用。
# Calculate the number of observations that constitute the top 20%
top_20_percent_count <- ceiling(length(data$charges) * 0.20)
# Sort the data frame by 'charges' in descending order to get the top charges
data_sorted <- data[order(-data$charges), ]
# Calculate the sum of the top 20% charges using the dynamically calculated count
top_20_percent_charges <- sum(data_sorted$charges[1:top_20_percent_count])
# Calculate the total sum of charges
total_charges <- sum(data$charges)
# Calculate the proportion of the top 20% charges relative to the total charges
proportion_top_20 <- top_20_percent_charges / total_charges
# Print the proportion
print(proportion_top_20)
[1] 0.5168555但如果是前30%的人呢? 則佔了總支出的64.27%。
top_30_percent_count <- ceiling(length(data$charges) * 0.30)
# Sort the data frame by 'charges' in descending order to get the top charges
data_sorted <- data[order(-data$charges), ]
# Calculate the sum of the top 20% charges using the dynamically calculated count
top_30_percent_charges <- sum(data_sorted$charges[1:top_30_percent_count])
# Calculate the total sum of charges
total_charges <- sum(data$charges)
# Calculate the proportion of the top 20% charges relative to the total charges
proportion_top_30 <- top_30_percent_charges / total_charges
# Print the proportion
print(proportion_top_30)
[1] 0.6427482這個結果令我很驚訝,因為這和我分析黑色星期五53萬筆消費數據的結果非常相近。
黑五消費數據中,前20%的人佔總消費的55%;醫療支出數據中,前20%的人佔總醫療支出的51%;
黑五消費數據中,前30%的人佔總消費的68%。醫療支出數據中,前30%的人約佔總醫療支出的64%。
也就是說現實世界幾乎就是少數的人佔了大部分的支出/消費,不過實務上不會那麼接近80/20分配,在我工作實證上與數據專案的分析當中,大概是70/30法則較多。
雙變量分析(Bivariate Analysis)
相關係數Heatmap圖
corrplot(cor_matrix, method = "square", type = "upper", tl.col = "black", tl.srt = 45,tl.cex = 0.7)
相關係數Heatmap中,抽菸習慣(smoker)與醫療支出(charges)之相關係數為0.7872,為高度正相關。 BMI與醫療支出(charges)之相關係數為0.1983,為低度正相關。
「抽菸習慣與性別」和醫療支出的關係
將人群依照性別與抽菸與否分為四個子群,觀察這四個子群的醫療支出有無區別? R Code如下。
ggplot(data1, aes(x = sex, y = charges, fill = smoker)) +
geom_boxplot() +
scale_fill_manual(values = c("#9ACD32", "#FF7F50")) +
theme_minimal()
可以發現抽菸者比沒抽菸者的醫療支出高,並且不隨性別不同而有所差異。
「抽菸習慣與年齡」和醫療支出的關係
ggplot(data, aes(x = age, y = charges, color = as.factor(smoker))) +
geom_point() +
geom_smooth(method = "lm", se = FALSE) +
labs(title = "Smokers and non-smokers") +
scale_color_manual(values = c("#FC642D", "#B13E53"),
labels = c("Non-smoker", "Smoker"))+
theme_minimal()
再來看年齡與醫療支出的關係。可以看到年齡愈高醫療支出也愈高,這其實也不意外,年紀愈大本身病痛也多,會有比較多的支出也很正常。另外,不分年齡,抽菸者普遍比無抽菸者有更高醫療支出。
「抽菸習慣與BMI」和醫療支出的關係
ggplot(data, aes(x = bmi, y = charges, color = as.factor(smoker))) +
geom_point() +
geom_smooth(method = "lm", se = FALSE) +
labs(title = "Smokers and non-smokers") +
scale_color_manual(values = c("#FC642D", "#B13E53"),
labels = c("Non-smoker", "Smoker"))+
theme_minimal()
可以觀察到BMI在無抽菸者中(橘色線)沒有很顯著的關係,但BMI在有抽菸者當中(紅色線)卻有非常顯著的正向關係。可以看見肥胖與抽菸習慣的雙重加乘之下,有抽菸者的醫療支出會隨BMI提高而增加,這是非常有趣的現象。
多元回歸分析(Multiple Regression Analysis)
目標變數是醫療支出,這是一個屬量變數,故可以建立多元回歸模型:

要如何求得最佳的迴歸斜率係數? 主流常見的方法有OLS(最小平方法)、MLE(最大概似法)、動差法等等,以下介紹OLS。
SSE為殘差平方和,我們希望SSE最小,才能找到最佳的迴歸線與係數:

一定有一個最佳的係數beta使得SSE最小,因此一階微分要為0:

可以導出最佳迴歸係數為:

一階微分為0只是尋找極小值的必要條件,因為極大值也是一階微分為0。必須再滿足充分條件,即二階微分為正定矩陣(positive-definite matrix):

以上是用矩陣來表達的推導過程,比較適合有統計學基礎的人。若是零基礎的讀者可以看我在統計學基本觀念與簡單線性回歸分析文章當中的圖解。
以下我用R語言來實作OLS:
#令第一個column為被解釋數矩陣 : Y
Y = as.matrix(data %>% select(charges))
#令其餘column為解釋變數矩陣 : X
X = as.matrix(data %>% select(constant, age, sex, bmi, children,
smoker, southwest, southeast, northwest))
beta_hat = solve(t(X)%*%X) %*% t(X)%*%Y
print(beta_hat)導出最佳回歸斜率如下:

當然更便捷的方法是直接調用R語言常用的「lm」包:
model <- lm((charges)~age+sex+bmi+children+smoker+
southwest+southeast+northwest,data=data)
summary(model)
結果如上,可以看到迴歸斜率是一樣的。其中年齡、bmi、抽菸習慣都是達到1%顯著水準的。
解讀係數上特別要注意的是性別(sex)、抽菸習慣(smoker)與居住地區等類別變數。這些類別變數一定要先經過one-hot encoding才能跑模型。以性別為例,我們令男生=1,女生等於0,在數學語言上其原理就是利用截距項的距離來表達兩者的差異。
以性別(sex)為例,係數為-131.3,由於比較基準為女生=0,因此係數意思是指「男生比女生平均少$131.3美元的醫療支出」。以抽菸習慣(smoker)係數23838.5為例,由於比較基準為無抽菸=0,因此意思是「抽菸者比沒抽菸者平均多$23838.5美元的醫療支出」。
至於BMI與年齡這種屬量變數該如何解釋呢? 以BMI的係數339.2為例,其意義為「每增加一單位的BMI,平均會增加$339.2美元的醫療支出」。以年齡的係數256.9為例,其意義為「每增加一單位的年齡,平均會增加$256.9美元的醫療支出」。
在解釋說明上一定要加上「平均」二字才精準,因為這只是常態分配下的期望值E(X),每個獨立的個體都會因為有干擾項而或多或少影響,換句話說是在E(X)上下擺動。
檢查共線性方法:變異數膨脹因子(VIF)
跑回歸前都必須要先檢查變數是否存在共線性(Collinearity),也就是變數是否高度重疊和相似。VIF的原理很簡單,模型中的每一個解釋變數視為被解釋變數進行輔助迴歸(auxiliary regression)。
例如我有X1 X2 X3等三個解釋變數,就是分別把X2 X3對X1跑一個迴歸,X1 X3對X2跑一個迴歸,X1 X2對X3跑一個迴歸,這樣我就能獲得三個判定係數(R square),可得VIF公式為:

一般而言VIF 小於10 即認定變數間無嚴重的共線性。換言之,輔助迴歸判定係數須在0.9 以下。而較嚴格的標準是VIF 小於5 才認定變數間無嚴重的共線 性,換言之,判定係數必須在0.8 以下。
vif_values <- vif(model)
print(vif_values)
結果中可見VIF 皆小於5,代表輔助迴歸判定係數皆在0.8 以下,由此可推論變數間沒有存在嚴重的共線性。
若存在共線性,雖然係數仍是不偏的,但標準誤會偏大會導致t值非常小,統計上會不顯著因此更容易接受虛無假設。一般解決方法是剔除變數、增加樣本數等;或者若願意犧牲一點不偏性,但堅持仍具有效性則可使用嶺迴歸(Ridge Regression)(廖崇智, 2019)。
假設檢定(Hypothesiss Testing)
為了回答「統計上某變數是否對醫療支出有顯著影響?」這個問題,我們必須對β1(斜率)進行顯著性檢定。
顯著水準5%下,令虛無假設:「β1等於零」;對立假設:「β1不等於零」
假設是否為零,意義在於檢定 X(解釋變數) 能否解釋 Y (被解釋變數)。 若係數為0,則係數斜率為水平線,則X無法解釋Y。如下圖:

這裡我們最有興趣的是抽菸習慣與BMI這兩個變數。
在smoker係數為0的虛無假設下,t統計量為57.723,而自由度1329,顯著水準1%的t分配臨界值為2.326。故拒絕X與Y不相關的虛無假設,因此smoker變數統計上顯著影響醫療支出。
在BMI係數為0的虛無假設下,t統計量為11.86,而自由度1329,顯著水準1%的t分配臨界值為2.326,故我們拒絕X與Y不相關的虛無假設,因此BMI變數統計上顯著影響醫療支出。
異質變異數(Heteroscedasticity)

異質變異數是指隨機變數的變異程度並不會完全相同。以上圖為例,假設x是讀書時間,y是考試成績,可以看到x1(每週讀2小時)大家的考試成績不會相差太多,大約落在20~30分;但是到了x3(每週讀10小時),每個人的讀書效率有差,考試成績可以小至20分,大至80分。這樣的資料分佈在實務上非常常見,必須小心處理之。
異質變異數存在時,OLS估計量仍為不偏估計量,且滿足一致性。因此先前估的抽菸係數,即抽菸會增加$23848的醫療費用仍是正確的, 但是會失去有效性,因此並非最佳線性不偏估計量(BLUE)。
換句話說,因為估出來的標準誤是偏誤的,會使得t檢定失效,也就是說抽菸係數中的 t 值可能沒有先前估出來的57那麼高。
為了檢測異質變異數,本文進行 Breusch-Pagan (BP)檢定。bptest() 檢定結果顯示:BP = 105.52, Df = 8, p = < 2.22e-16,p值趨近於0,因此拒絕樣本為同質變異數的虛無假設,發現存在異質變異數問題。如何解決呢? 我嘗試了兩種方法: 1.取對數 2.穩健標準誤。
取對數
將目標變數醫療費用取對數後,可以看到從右尾分配趨向常態分配。


取對數後,形成log-level model如下:

對該模型進行Breusch-Pagan (BP)檢定。 bptest() 結果顯示: BP = 48.866, df = 8, p-value = 6.745e-08 。雖然情況減輕很多,但仍存在異質變異數問題。
穩健標準誤(Robust Standard Errors)
穩健標準誤又稱懷特異質變異數下一致性標準誤 (Heteroskedasticity-consistent standard errors, HCEs),目前有HC0~HC4等五種版本,這裡採用最初懷特於1980年提出的HC0版本:

其中diag()是原回歸跑OLS後得到的殘差平方放在對角線上,並且所有非對角線上的元素都為零的對角矩陣。R code 如下:
OLS_Regression <- lm(charges~age+sex+bmi+children+smoker+
southwest+southeast+northwest, data=data)
robust_summary <- coeftest(OLS_Regression, vcov. = vcovHC(OLS_Regression5, type = "HC0"))
robust_summary要注意的是,穩健標準誤差不影響模型本身的殘差,它們僅僅調整了系數的標準誤差計算方式,也就是說模型本身的殘差仍存在異質變異數,因此不需要再次進行BP test。接下來應當使用這些穩健標準誤差進行假設檢定或信賴區間的計算。
因此我捨棄原本的標準誤,採上式的穩健標準誤修正後再次進行假設檢定。
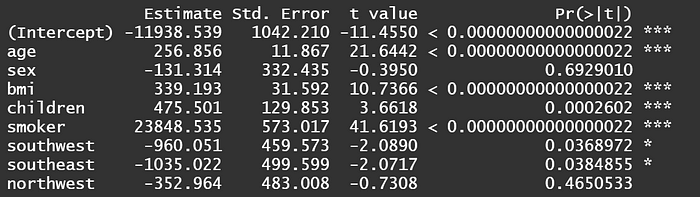
結果顯示,抽菸的係數仍維持$23848不變,但t值從原先的57降到41。而p值一樣仍在幾兆分之一,因此抽菸這個變數即使經過標準誤修正後,它還是非常顯著的,可以用來解釋醫療費用的高低。
預測 : 機器學習 vs 線性回歸
我們比較XGBoost(極限梯度提升), Random Forest(隨機森林)等機器學習模型與Linear Regression(線性回歸)的預測能力。
這三個模型皆使用RMSE來比較精準度。RMSE公式如下:

其中Yi Hat是模型的預測值,Yi則是實際值。因此這兩者之差是愈小愈好,經過平方與開根號後,最後的RMSE是愈小愈好。

可以看到XGoost的RMSE:4941表現最為優秀,而線性回歸的RMSE: 6568表現最差,在此performance我們不寫「差」而是寫「普通」,是因為線性回歸還是比隨機亂猜好太多了,只是對手(機器學習)太強了,在沒有機器學習的年代,線性回歸用來預測還是不錯的。
比較預測能力 : 抽樣本
只看RMSE可能會有些無感,在此抽了一個樣本: 56歲的男性,就叫他John吧! 可以看到XGBoost預測John的醫療費用最接近。

另外再抽一個樣本: 28歲女性,就叫她Marry吧!

可以看到Linear Regression預測Marry的醫療費用最接近,這就有趣了。因此我從「非抽菸者(non-smoker)」當中再抽了一些樣本來看看。

預測最接近者為紅色,預測距離最遠者為綠色。可以觀察到線性回歸的綠色區塊最多,預測能力依舊不及機器學習。然而case8與case10的預測表現卻是線性回歸最好。為何線性回歸在預測「無抽菸者」的表現有時候優於機器學習呢? 以下是解釋。

由於線性回歸在立體空間是一個平面,代表資料點能用最簡單的線性關係來解釋(見上圖)。 線性回歸預測的結果很準代表這兩個case的實際值和這塊平面的距離並不遠,故線性回歸捕捉到這樣的線性關係而優於了機器學習。而機器學習則是在資料為非線性關係時預測能力較強。
線性回歸還有一個優點是能知道X上升一單位對於Y的邊際效果,這是機器學習做不到的。 然而就預測的整體表現來看,機器學習(RMSE: 4941)還是比線性回歸好(RMSE: 6568),因此仍推薦使用機器學習來預測醫療費用。
最後我再從「抽菸者」當中抽了一些樣本,可以觀察到綠色區塊全是線性回歸,其預測能力遠不及機器學習。

為何線性回歸在預測「有抽菸者」的表現如此差? 是因為對手(機器學習)太強? 或者自己太弱?我們提供了一個解釋:「可能都有!」

本文研究的資料是醫療費用的高低,其中抽菸這個變數是虛擬變數(1=有抽菸) 。很不巧地,上方盒鬚圖可以看到有抽菸和沒抽菸的人本身醫療費用差距就很大,這會使得該變數非常顯著(p值趨近於0),且回歸係數高達23848。
如此一來,一旦有抽菸不分男女老少會直接增加$23848的醫療費用,若這樣簡單粗暴地分成有無抽菸,這對於線性回歸而言就無法細膩地預測。
然而抽菸本身是可以被量化成數字的,例如每個禮拜抽幾包菸,每個月花多少菸錢,或者抽菸指數(1~10)等等。若有這樣的資料,相信線性回歸的預測表現不會太差。
結論
本文利用R語言對1338名美國國民資料建立多元回歸模型,實證結果中:
1. 前30%的人的醫療支出佔了總醫療支出的64.27%,呈現70/30法則。
2. 相關係數Heatmap中,抽菸習慣與醫療支出相關係數為0.7872,為高度正相關。
3. 抽菸者醫療支出比無抽菸者平均高出US$23,848。
4. Breusch-Pagan (BP)檢定中發現存在異質變異數問題。經過穩健標準誤修正後,抽菸的係數仍維持$23848不變,但t值從原先的57降到41。而p值一樣仍在幾兆分之一,因此係數仍非常顯著,可以用來解釋醫療費用的高低。
5. 最後比較整體預測能力,其中XGboost(RMSE:4941)相較線性回歸(RMSE:6568)更精準,然而線性回歸預測某些樣本較佳,對此我們也提出解釋:線性回歸預測的結果很準代表這兩個case的實際值和這塊平面的距離並不遠,故線性回歸捕捉到這樣的線性關係而優於了機器學習。
參考文獻:
- 廖崇智(2019),「提綱挈領學統計(第八版)」
- 陳強(2014),「高級計量經濟學及 Stata 應用」








