黑色星期五(Black Friday)由來
黑色星期五(Black Friday)為美國感恩節後一天,這天一般被視為是聖誕採購季的開始,通常商場會推出大量的打折優惠、促銷活動。由於美國的商場一般以紅筆記錄赤字,以黑筆記錄獲利,而感恩節後的這個星期五人們瘋狂的搶購使得商場利潤大增,因此稱作黑色星期五。

理解數據

該資料集有9個欄位:
1. User_ID(用戶編號) : 一個用戶會消費多次,因此不是唯一值
2. Product_ID(產品編號)
3. Gender:(性别,類別變數)
4. Age(年齡)
5. Occupation(職業,類別變數):共20種類別。但無法得知背後意涵
6. City_Category(城市,類別變數):分A、B、C三種類別的城市,但無法得知背後意涵
7. Stay_In_Current_City_Years(在目前城市停留幾年) : 0~4+ 年
8. Marital_Status(婚姻狀況,類別變數) : 0表示未婚,1表示已婚
9. Purchase:消費金額(美元)
要特別注意User_ID有重複值,即代表每人會消費一種(含)以上商品,因此這53萬7577筆數據必須視為「總消費人次」而非「總消費人數」。
問題意識(problematic)
觀察完資料集後,其中有幾個特徵令我相當好奇:性別、年齡、婚姻狀態,因此我列出以下問題:
Q : 總消費人數為何? 總消費金額為何? 平均消費金額為何? 消費多少商品數量?
Q : 前十大消費金額為何? 對應性別、年齡為何?
Q : 各年齡層人數占比為何? 哪個年齡層消費力道較強?
Q : 性別占比為何? 何者消費力道較強?
Q : 已婚與未婚佔比為何? 何者消費力道較強?
Q: 將人群以年齡+性別+結婚與否再拆分成更小的子群,何者消費力道較強?
接下來就要利用數據分析的方法針對問題一一回答。
數據清洗(data cleaning)
通常一個資料集中在採集數據時可能會有髒數據(dirty data)產生,例如:缺失值(Null)、異常值(極大值、極小值)、重複值等等。因此進行分析前,數據清洗是相當重要的步驟,甚至占了數據分析工作大半的時間。如此才能確保數據是乾淨的,並且分析的結果是精確無誤的。
由於是從Kaggle網站取得的現成數據,並不是自己爬蟲下來的原始數據,因此不須做太多預處理,但我們還是能做一些檢查。
檢查重複值
在以往工作實務上,重複值是偶爾會遇到的情況。由於一個人會同時消費一種以上商品,User_ID必然會重複,因此必須同時檢查User_ID與Product_ID是否有重複值。
SELECT [User_ID],[Product_ID]
FROM [master].[dbo].[BlackFriday]
GROUP BY [User_ID],[Product_ID]
HAVING COUNT(*)>1
撈不出資料,因此可確定沒有重複值。
檢查異常值
實務中較少遇到異常值,也許這和我之前待的是採購/供應鏈部門有關。通常user都是填料號的cost或quotation,不會有人填到負值,因此在原始的excel 檔案中讀進來後也不會有誤。反而要小心的是如果我們將cost rollup,小數點要注意計算到第四位甚至第八位,避免設定兩位使得四捨五入的時候導致cost rollup時錯誤。
在此我試著找「Purchase」欄位中小於0的值。
SELECT * FROM [master].[dbo].[BlackFriday]
WHERE Purchase < 0
撈不出資料,因此可確定沒有異常值。
檢查缺失值
工作上很常出現缺失值,不外乎user在填資料時沒有照格式填;或者是產品本身的family name在A表改了但procurement manager不知道,所以mapping table會對接不上而導致缺失值;又或者產品本身太新,family name根本沒有被procurement manager建在mapping table等等。
以上問題都會導致最後的總表上會有缺失值,最終結果會高估或低估Weighted Cost,如此一來自動化報表的數字會和procurement manager手上的數字不一致。
以下我挑UserID與Purchase看是否有缺失值,若其中有一個缺失都會在計算平均數時產生偏差,導致錯誤的結論。
SELECT * FROM [master].[dbo].[BlackFriday]
WHERE User_ID IS NULL OR Purchase Is NUL撈不出資料,因此可確定沒有缺失值。
探索式資料分析 (Exploratory Data Analysis, EDA)
在上述數據清洗與檢查的步驟完成後,就可以根據問題來分析。
Q : 總消費人數為何? Ans: 5891人
SELECT COUNT(DISTINCT [User_ID]) AS HeadCount
FROM [master].[dbo].[BlackFriday]
Q: 總消費金額為何? Ans: 50億1766萬8378元
SELECT SUM([Purchase]) AS TotalPurchase
FROM [master].[dbo].[BlackFriday]
Q: 每人平均消費金額為何? Ans: $ 85萬1751元
SELECT SUM([Purchase])/COUNT(DISTINCT [User_ID]) AS Purchase_Per_Person
FROM [master].[dbo].[BlackFriday]
$ 85萬1751元這數字看起來不太合理,但平均數的誤區就是:當少數個體消費非常巨大時,平均消費數字也會提高。簡單說就是我和比爾蓋茲的平均身價有上百億美元一樣。
寫到這我又好奇一個問題 : 每人平均消費是否遵循柏拉圖法則(Pareto principle, 又稱80/20法則)? 換句話說,是否少數的人佔了絕大多數的消費?
我在工作上也曾好奇過柏拉圖法則這個問題。當時負責forecast report,我手上有每個產品線的每個系列的實際出貨量資料。
我想看是否幾個少數的「明星」系列佔了絕大多數的出貨量? 我的實證結果是 : 「真的有!」 在筆電這個產品線中大約是30%的系列占了72%的出貨量! 這是非常有趣的現象。現在我們來觀察黑五是否也有這個現象?
SELECT SUM(Purchase_each_Person)/(SELECT SUM([Purchase]) AS TTL_Purchase
FROM [master].[dbo].[BlackFriday]) AS Top20Percent_Purchase_Rate
FROM (
SELECT TOP 20 PERCENT Purchase_each_Person FROM (
SELECT SUM([Purchase]) AS Purchase_each_Person
FROM [master].[dbo].[BlackFriday]
GROUP BY [User_ID]
) AS Purchase_each_Person
ORDER BY Purchase_each_Person DESC
) AS Top20Percent_Purchase;
結果顯示前20%消費最強的那群人(大約1178人)大約佔總消費55.45%。雖然不到80%但也佔了一大半了。我也好奇若是top30%那群人會佔多少消費?
SELECT SUM(Purchase_each_Person)/(SELECT SUM([Purchase]) AS TTL_Purchase
FROM [master].[dbo].[BlackFriday]) AS Top30Percent_Purchase_Rate
FROM (
SELECT TOP 30 PERCENT Purchase_each_Person FROM (
SELECT SUM([Purchase]) AS Purchase_each_Person
FROM [master].[dbo].[BlackFriday]
GROUP BY [User_ID]
) AS Purchase_each_Person
ORDER BY Purchase_each_Person DESC
) AS Top30Percent_Purchase;
結果顯示前30%消費最強的那群人(大約1767人)佔總消費68.43%,這和我在工作時的實證結果蠻相似,也就是說現實世界中是那關鍵少數人掌握世界上大部分的消費。這也讓我好奇下一題: 前十大金字塔頂尖的人每人消費多少?
Q : 前十大消費金額為何? 對應性別、年齡為何?
SELECT TOP(10)* FROM (
SELECT DISTINCT
User_ID,
Gender,
Age,
SUM([Purchase]) OVER (PARTITION BY User_ID) AS TTL_PPP
FROM [master].[dbo].[BlackFriday]
) AS A
ORDER BY TTL_PPP DESC
前十大消費非常驚人,並且全為男性,年齡分布皆為青壯年人口。
Q : 各年齡層人數占比為何? 哪個年齡層消費力道較強?
WITH A AS (
SELECT
DISTINCT Age,
SUM([Purchase]) OVER (PARTITION BY Age) AS TTL_Pur_Age
FROM [master].[dbo].[BlackFriday]
),
B AS (
SELECT
DISTINCT Age, COUNT(DISTINCT User_ID) AS HC
FROM [master].[dbo].[BlackFriday]
GROUP BY Age
)
SELECT
A.Age,
TTL_Pur_Age,
HC,
ROUND(CAST(HC AS FLOAT) / SUM(CAST(HC AS FLOAT)) OVER(),2) AS HC_rate,
TTL_Pur_Age/HC AS Avg_PPAge
FROM A
INNER JOIN B
ON A.Age = B.Age
ORDER BY TTL_Pur_Age/HC DESC
這裡要定義什麼是「消費力道」,在此我定義為「平均每人消費」。可以看到26-35歲這個區間的平均每人消費最高,另外人頭數的佔比也是最高的(34.8%)。有趣的是消費力道最弱的是55歲以上族群,第二弱的反而是17歲以下經濟能力尚未獨立的族群。
Q : 性別占比為何? 何者消費力道較強?
SELECT
GenHeadC.Gender,
PurchaseByGen/HeadCount_EachGen AS AvgPerchase_ByGen,
GenDisRate=CAST(HeadCount_EachGen/TTLHeadCount AS DECIMAL(10,3)) FROM (
SELECT
Gender,
HeadCount_EachGen=CAST(COUNT(Gender) AS FLOAT),
TTLHeadCount=CAST((SELECT COUNT(DISTINCT User_ID) FROM [master].[dbo].[BlackFriday]) AS FLOAT) FROM(
SELECT DISTINCT [User_ID],[Gender]
FROM [master].[dbo].[BlackFriday]
) AS ID_Gen GROUP BY Gender
) AS GenHeadC
INNER JOIN(
SELECT Gender, SUM(Purchase) AS PurchaseByGen
FROM [master].[dbo].[BlackFriday] GROUP BY Gender
) AS GenderPur
ON GenHeadC.Gender = GenderPur.Gender
ORDER BY PurchaseByGen/HeadCount_EachGen DESC
可以看到男性的人頭數的佔比較高(71.7%),平均每人消費也較高。由此推論男性消費力道較強。
Q : 已婚與未婚佔比為何? 何者消費力道較強?
SELECT
MSHeadC.Marital_Status,
PurchaseByMS/HeadCount_EachMS AS AvgPerchase_ByMS,
MSDisRate=CAST(HeadCount_EachMS/TTLHeadCount AS DECIMAL(10,3)) FROM (
SELECT
Marital_Status,
HeadCount_EachMS=CAST(COUNT(Marital_Status) AS FLOAT),
TTLHeadCount=CAST((SELECT COUNT(DISTINCT User_ID) FROM [master].[dbo].[BlackFriday]) AS FLOAT) FROM(
SELECT DISTINCT [User_ID],[Marital_Status]
FROM [master].[dbo].[BlackFriday]
) AS ID_MS GROUP BY Marital_Status
) AS MSHeadC
INNER JOIN(
SELECT Marital_Status, SUM(Purchase) AS PurchaseByMS
FROM [master].[dbo].[BlackFriday] GROUP BY Marital_Status
) AS MSPur
ON MSHeadC.Marital_Status = MSPur.Marital_Status
ORDER BY PurchaseByMS/HeadCount_EachMS DESC
未婚族群(此為虛擬變數, 0=未婚)的人頭數佔比稍高(58%),平均消費較高。
Q: 將人群以年齡+性別+結婚與否再拆分成更小的子群,何者消費力道較強?
SELECT
MutiInfo_HC.MultiInfo,
PurchaseByMI/HeadCount_EachMI AS AvgPerchase_ByMI,
MIDisRate=CAST(HeadCount_EachMI/TTLHeadCount AS DECIMAL(10,2)) FROM (
SELECT
MultiInfo,
HeadCount_EachMI=CAST(COUNT(MultiInfo) AS FLOAT),
TTLHeadCount=CAST((SELECT COUNT(DISTINCT User_ID) FROM [master].[dbo].[BlackFriday]) AS FLOAT) FROM(
SELECT [User_ID], [MultiInfo] FROM (
SELECT DISTINCT [User_ID], MultiInfo = (RTRIM(Gender) + '_' + RTRIM(Marital_Status) + '_' + Age)
FROM [master].[dbo].[BlackFriday]
) AS ID_MultiInfo_Raw
) AS ID_Multi GROUP BY MultiInfo
) AS MutiInfo_HC
INNER JOIN(
SELECT MultiInfo, SUM(Purchase) AS PurchaseByMI FROM (
SELECT MultiInfo = (RTRIM(Gender) + '_' + RTRIM(Marital_Status) + '_' + Age), Purchase
FROM[master].[dbo].[BlackFriday]) AS MultiInfo_Pur_Raw GROUP BY MultiInfo
) AS MutiInfoPur
ON MutiInfo_HC.MultiInfo = MutiInfoPur.MultiInfo
ORDER BY PurchaseByMI/HeadCount_EachMI DESC

結果中,「男性+未婚+26~35歲」的族群平均消費最強,人頭數佔比也是最多(16%)。其次是「男性+已婚+26~35歲」的族群,第三名則是「男性+未婚+36~45歲」的族群,相當有趣。是否該族群買的是自己要的東西,或者是替家人/朋友/伴侶一起買呢? 若能有消費的商品種類就能推測之。
而「女性+已婚+55歲以上」的族群平均消費最低,其次是「女性+未婚+55歲以上」的族群。看過賣場在黑五時的開門影片後,其實也不難想見。賣場開業瞬間每個人跟喪屍一樣猛衝,甚至很多人還摔倒。搶到商品後還要使力拿走,對一個行動不便的婦人不太會衝第一線去賣場。
PowerBI Dashboard
最後,我們串接PowerBI製作儀表板。在先前的工作中也頻繁地使用PowerBI,user可以藉由篩選器來篩選想要的資料,例如年份/產品線/系列/當月版本or上月版本.....等等。對於user而言,PowerBI友善的UI介面下可以看他們想看的內容是相當方便的。
但對我來說缺點是匯入資料時需要一定時間,也因此要和團隊溝通是否只存最近3個月或6個月版本的forecast report,以節省匯入時間。

以上是黑色星期五消費的PowerBI Dashboard。最左上角通常會放字卡(Card),這也是user或主管第一個會看到的,因此都會放上最基本的資訊。
以先前工作為例,當時放的是Total Spending, Material spending, MVA (Manufacturing Value Added)spending, Total Quantity(=shipment)等四個指標。而在黑五資料集當中,總消費、總人數、總平均消費是三個我認為最基本的資訊,可以讓user一下就掌握該資料。
其他的平均消費by 年齡, By 性別以及消費者的人數分配等等在上面的SQL都已經分析過,而視覺化後更加清晰。其中的巧思是不使用過度豐富的顏色。《Google必修的圖表簡報術》書中強調過要屏除調無用資訊,讓user負擔降低,所以我僅僅用綠色標出最高/最大的佔比。
右上角這種smooth的每人平均消費分配圖沒辦法在PowerBI上畫出來,因此我是在python畫完後串接過來,python code如下。
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
from matplotlib.ticker import ScalarFormatter
from matplotlib.ticker import FuncFormatter
# Function to format large numbers into readable text
def format_large_numbers(x, pos):
if x >= 1e6:
return '{:.0f}M'.format(x * 1e-6)
elif x >= 1e3:
return '{:.0f}K'.format(x * 1e-3)
else:
return '{:.0f}'.format(x)
# Group by User_ID and calculate the total purchases for each user
grouped_df = df.groupby('User_ID')['Purchase'].sum().reset_index(name='TTLPurchase_by_Person')
# Sort the DataFrame by TTLPurchase_by_Person in descending order
sorted_df = grouped_df.sort_values(by='TTLPurchase_by_Person', ascending=False)
# Plotting the smooth distribution plot
plt.figure(figsize=(10, 6))
plt.xlabel('') # Hide x-axis label
plt.ylabel('') # Hide y-axis label
sns.kdeplot(sorted_df['TTLPurchase_by_Person'], bw_adjust=0.5, fill=True)
# Customize x-axis tick labels to display numbers as text
plt.gca().xaxis.set_major_formatter(FuncFormatter(format_large_numbers))
# Hide x-axis and y-axis labels
plt.gca().set_xlabel('')
plt.gca().set_ylabel('')
plt.tight_layout()
plt.show()柏拉圖分配機率密度函數如下:
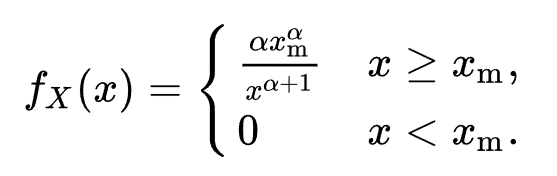
當X>= Xm時pdf才有效。當Xm=1時機率分配圖如下:

α = tail index,我們看α =1 的情況,此時柏拉圖分配的機率密度函數會變成1/X^2,所以當X增長時機率會呈現指數下降。另外在UC Berkeley D-Lab的文章中表示:
....the "80–20 Rule” is represented by a distribution with alpha equal to approximately 1.16.
故alpha=1.16時會呈現80/20法則的分配。可以看到PowerBI儀表板右上角的消費分配非常接近柏拉圖分配。換句話說絕大部分的人的消費都很低,都集中在$0~2m之間,而大筆的消費(8M+)只有少數的人負擔得起。所以導致了上述的結果:僅僅30%的人佔了68.43%的總消費。
結論
本文以MS SQL分析53萬筆黑色星期五消費數據,分析結果中 :
1. 男性的人數的佔比較高(71.7%),平均每人消費也較高。由此推論男性消費力道較強。
2. 前30%消費最強的那群人佔總消費68.43%,消費分配趨向70/30法則,而非傳統的80/20法則。
3. 平均消費最強是「男性+未婚+26~35歲」的族群,同時人數佔比也是最多(16%)。而「女性+已婚+55歲以上」的族群平均消費最低。








